
With the growing demand for LLMs and AI ML services, research efforts have focused on finding ways to make these models more efficient and accessible for industries across all domains. One approach that has gained significant attention is quantization, which involves representing weights and activations of neural networks using fewer bits without compromising much on the model’s accuracy. In this article, we aim to explore deeper into the topic of quantization and examine how it works across different LLM formats.
Furthermore, we will provide a step-by-step guide on loading and quantizing LLMs using a widely adopted library for inference, shedding light on the usability and benefits of various quantization methods.
What is a quantized language model or quantization in LLM?
A Large Language Model is represented by a bunch of weights and activations. These values are generally represented by the usual 32-bit floating point (float32) datatype.
The number of bits tells you something about how many values it can represent. Float32 can represent values between 1.18e-38 and 3.4e38, quite a number of values! The lower the number of bits, the fewer values it can represent. As you might expect, if we choose a lower bit size, then the model becomes less accurate but it also needs to represent fewer values, thereby decreasing its size and memory requirements.
Quantization in large language models (LLM) is a technique that involves converting the model weights from high-precision floating-point representation to lower-precision floating-point (FP) or integer (INT) representations, like 16-bit or 8-bit. This process significantly reduces the model size and improves inference speed without sacrificing much accuracy. Moreover, quantization enhances the model’s performance by decreasing memory bandwidth requirements and boosting cache utilization.
How does Quantization work with LLM in different formats?
The Future of DevOps in Product Engineering
Firstly We know that we can directly load LLM using the Transformers library from hugging face through the below method: –

We can directly quantize the Model through the Bits and Bytes Module for Inference or Training.
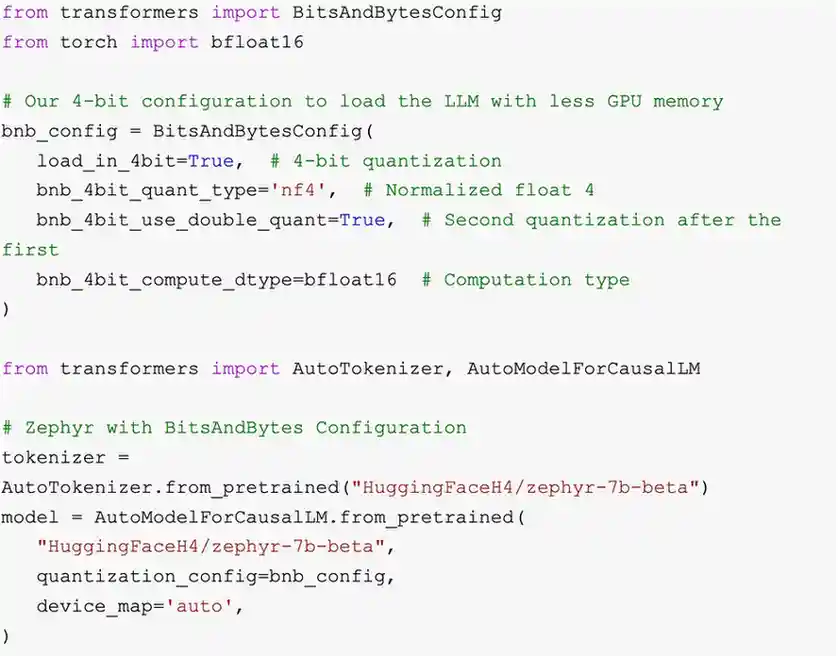
This configuration allows us to specify the quantization levels we are aiming for. Generally, we aim to represent the weights with 4-bit quantization but conduct the inference in 16-bit. This is essentially how we can perform quantization directly on the model.
These parameters collectively optimize GPU memory usage for a model, Enabling 4-bit quantization (`load_in_4bit=True`) reduces the memory footprint by representing weights using only 4 bits. The choice of ‘nf4’ as the quantization type (`bnb_4bit_quant_type=’nf4’`) signifies the use of a normalized floating-point format with 4 bits. Introducing double quantization (`bnb_4bit_use_double_quant=True`) refines the representation through a second quantization pass. Computation in bfloat16 (`bnb_4bit_compute_dtype=bfloat16`) enhances memory efficiency with a 16-bit floating-point format. The automatic device mapping (`device_map=”auto”`) ensures efficient GPU utilization for large models. Together, these settings strike a balance between reduced memory usage and model performance on GPUs.
This is all about Quantization in Transformers.
Quantization in Different Format
Now let’s get to the part where we can directly use different quantized model formats in the interface and use them as we like.
Now there are multiple formats of the quantized model.
GGUF, GGML, and GPTQ are prominent file formats utilized for quantized language models.
GGML and GGUF
GGUF and GGML are creations of Georgi Gerganov, while GPTQ is grounded in research by Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh.
Llama.cpp, developed by Georgi Gerganov, is versatile, supporting both GGUF and GGML formats. It also accommodates other formats such as bin and safetensors.
GGUF, introduced as GGML’s successor, accommodates various models, including LLaMA models. It addresses limitations inherent in GGML.
Frameworks like Transformers, Llama.cpp, koboldcpp, and ExLlama exhibit varying degrees of support for multiple quantization formats. Some frameworks may require specific formats. Different frameworks like ctransformers provide similar interfaces for model usage, allowing compatibility with various model formats.
Safetensors can be utilized with Transformers but not with Llama.cpp. The effectiveness of the “Use in Transformers” button on the Hugging Face site might not be universal for all hosted models.
Quantization methods developed by Georgi Gerganov (GGML/GGUF) facilitate CPU-based inference for LLaMA models. These methods include file formats that embed metadata within the model file.
GGUF files include all necessary metadata in the model file, making additional files unnecessary, except for the prompt template.GGML is no longer supported by llama.cpp, and GGUF is recommended for usage instead, even if documentation suggests GGML models.
GGUF represents an upgrade over GGML, addressing limitations and enhancing user experience. GGUF allows for extensibility and supports various models beyond llama.cpp, providing stability and compatibility. Transitioning to GGUF may require time, but it aims to streamline the user experience and support a wider range of models.
Let’s see how we can use LLM in GGUF format using llamacpp in code.


GPTQ
GPTQ stands out as a quantization algorithm specifically designed for GPU-based models. Support is provided by AutoGPTQ and ExLlama.GPTQ is a post-training quantization (PTQ) method for 4-bit quantization that focuses primarily on GPU inference and performance.
GPTQ is a Layerwise Quantization algorithm. GPTQ quantized the weights of the LLM one by one in isolation. GPTQ converts the floating-point parameters of each weight matrix into quantized integers such that the error at the output is minimized.
The idea behind the method is that it will try to compress all weights to a 4-bit quantization by minimizing the mean squared error to that weight. During inference, it will dynamically dequantize its weights to float16 for improved performance whilst keeping memory low.
Why GPTQ?
Thanks to their breakthrough performance, LLMs set themselves apart from traditional Language Models (LM). Yet, this comes at a massive inference cost. Most LLMs have billions, if not tens of billions, of parameters. Running these models requires 100s gigabytes of storage and multi-GPU servers, which can be prohibitive in terms of cost.
Two active research directions aim to reduce the inference cost of GPTs. One avenue is to train more efficient and smaller models. The second method is to make existing models smaller post-training. The second method has the advantage of not requiring any re-training, which is prohibitively expensive and time-consuming for LLMs. GPTQ falls in the second category.
Let’s see how GPTQ can be used in Code.


AWQ
A new format on the block is AWQ (Activation-aware Weight Quantization) which is a quantization method similar to GPTQ.AWQ represents a low-bit quantization algorithm, while AutoGPTQ serves as a quantization library rooted in the GPTQ algorithm. AutoGPTQ is accessible via Transformers. There are several differences between AWQ and GPTQ as methods but the most important one is that AWQ assumes that not all weights are equally important for an LLM’s performance.
In other words, there is a small fraction of weights that will be skipped during quantization which helps with the quantization loss.
As a result, their paper mentions a significant speed-up compared to GPTQ whilst keeping similar, and sometimes even better, performance.
To use this example of AWQ, we first need to disconnect the runtime before installing the vllm dependency. There can be dependency conflicts with the packages we installed previously, so it is best to start from scratch.



Different model file formats, such as GGUF, GGML, GPTQ, and AWQ, are designed to accommodate diverse quantization approaches and frameworks. Another optimization technique involves reducing GPU usage during model loading through sharding. In sharding, the model is effectively divided into smaller pieces or shards.
Conclusion
There are several quantization algorithms available for deep learning models such as Safetensors, AWQ, GPTQ, and GGUF. While some frameworks have broader support for these formats than others, AutoGPTQ and ExLlama offer comprehensive coverage of GPTQ quantization for GPU-based models, and GGUF provides CPU-friendly options optimized for LLaMA models through its embedded metadata feature.
To utilize LLMs in GGUF format, developers can follow the steps outlined in this tutorial using the popular llama.cpp library alongside HuggingFace Model Hub functionality to easily obtain and deploy pre-trained models. As the field continues to evolve, users should remain aware of potential changes and updates related to quantization methods and their associated libraries.
Ultimately, understanding and utilizing the appropriate format and toolset will depend on individual project requirements regarding desired computational performance versus hardware accessibility.
Read more: “Best Large Language Models in 2026: The Ultimate Guide For Enterprises“



