
Enterprise adoption of AI is accelerating, but so is the risk that comes with it. Every day, people paste sensitive data into tools like ChatGPT and Google Gemini to move faster. The trade-off is rarely visible: confidential information leaving their network and entering third-party systems they don’t control.
This is not a policy problem, but it’s a structural one. As long as AI relies on external APIs, data leakage remains an inherent risk.
This guide outlines a different approach. Instead of sending data to the model, you bring the model to your data. By fine-tuning open source SLM (Small Language Models) inside your own infrastructure, you can build enterprise AI systems that are private, compliant, and fully controllable, without sacrificing capability.
The Problem: Data Leakage in Enterprise AI
Every day, employees across the globe are pasting internal memos, financial reports, customer records, and proprietary source code into cloud-based AI tools like ChatGPT and Google Gemini. The intention is innocent — they want help summarising, drafting, or analysing. The consequence can be catastrophic.
What is Data Leakage?
Data leakage occurs when sensitive, confidential, or proprietary information is unintentionally exposed to parties outside the intended audience. In the context of enterprise AI, it happens the moment your employee’s prompt, containing customer PII, internal strategy, or financial data, leaves your network and travels to a third-party cloud server.
Real-world analogy
Imagine photocopying your company’s confidential Q3 earnings forecast and handing it to a stranger to summarize it. That stranger might be trustworthy, but you have no contract, no audit trail, and no guarantee they won’t remember it.
Categories of Sensitive Enterprise Data
- Financial data: quarterly forecasts, M&A targets, revenue breakdowns, investor reports
- Customer PII: names, emails, account numbers, health records, regulated under GDPR and HIPAA
- Intellectual property: source code, product roadmaps, patents, trade secrets
- HR data: salary bands, performance reviews, disciplinary records
- Legal communications: contracts, litigation strategy, privileged attorney-client memos
Why Cloud AI Creates Structural Risk
When using a cloud-based LLM via API:
- Your data is transmitted over the internet to an external server
- The model provider processes it in their compute environment
- Some providers have historically used API inputs to improve model quality
- You have no visibility into how the data is stored, processed, or retained
GDPR Article 28 requires a Data Processing Agreement before sending EU personal data to any third party. HIPAA mandates a Business Associate Agreement for any PHI. Many cloud AI providers’ standard terms do not satisfy these requirements for zero-retention guarantees.
The Solution: SLMs vs LLMs
What is a Large Language Model (LLM)?
An LLM is a neural network trained on hundreds of billions to trillions of tokens of text, essentially a large fraction of the indexed internet, combined with books, code, and scientific papers. Examples include GPT-4 (OpenAI), Claude 3 (Anthropic), and Gemini (Google). These models have hundreds of billions of parameters and require datacenter-scale infrastructure to run. You access them via an API – meaning your data leaves your environment.
Also read: Best Large Language Models in 2026: The Ultimate Guide For Enterprises
What is a Small Language Model (SLM)?
An SLM is the same fundamental architecture as an LLM, but deliberately constrained in size, typically between 1 billion and 13 billion parameters. This makes them:
- Deployable locally: they fit on a single enterprise-grade GPU server
- Fine-tunable: you can continue training them on your own data in hours, not weeks
- Privately hosted: no internet dependency once downloaded, zero external data transmission
- Cost-efficient: inference costs a fraction of cloud API fees at scale
Think of an LLM as a vast public library: extraordinarily knowledgeable, but located in someone else’s city. An SLM is your own specialist reference shelf: smaller, purpose-built, and entirely within your walls.
SLM vs LLM – Head-to-Head Comparison
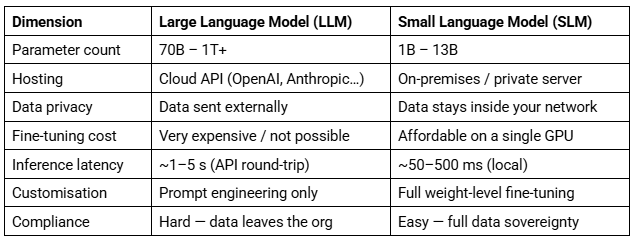
Latency figures are illustrative averages. Actual performance depends on hardware, quantisation, and batch size.
When is an Open Source SLM the Right Choice?
An SLM is the right tool when your organisation has any of the following requirements:
- Regulatory obligation to prevent data from leaving your jurisdiction (GDPR, HIPAA, SOC 2, ISO 27001)
- Proprietary knowledge the model must understand — internal jargon, processes, product names
- High query volume makes per-token API costs unsustainable
- Air-gapped or highly restricted network environments
- Need for full auditability and control of model weights and outputs
When to still use a cloud LLM For non-sensitive tasks, marketing copy, general research, and public data analysis, cloud LLMs remain excellent. A hybrid strategy is often optimal: SLM on-prem for sensitive work, cloud LLM for non-confidential creative and exploratory tasks. |
What Does Fine-Tuning an SLM Mean?
Pre-training vs Fine-tuning
Open source SLM models arrive as general-purpose models: they understand English (and many other languages), can follow instructions, and have broad world knowledge. But they do not know:
- Your company’s internal terminology or product names
- The specific format your reports follow
- Your compliance policies or approved phrasing
- Domain-specific financial, legal, or medical vocabulary at expert depth
Fine-tuning is the process of continuing the model’s training on your own curated dataset. You are not starting from scratch, but you are steering an already-capable model towards your specific domain, tone, and tasks. Hence, the result is a model that behaves like a specialist who already works at your company.
How Fine-tuning Works — The Technical Mechanism
Modern fine tune SLM uses techniques such as LoRA (Low-Rank Adaptation) or QLoRA (Quantised LoRA). Instead of updating all billions of parameters in the base model — which would require enormous compute — LoRA inserts small trainable adapter layers alongside the frozen original weights.
This means:
- Base model stays frozen: original capabilities are preserved
- Adapters are small: the entire fine-tuned delta is often under 500 MB
- Training is fast: a 7B model can be fine-tuned on 1,000 examples in under 2 hours on one GPU
- Multiple fine-tunes: you can maintain different LoRA adapters for different departments (finance, legal, HR)
Types of Fine-tuning
- Supervised Fine-tuning (SFT): you provide instruction-output pairs (e.g., ‘Summarise this contract’ → [correct summary]). The most common approach.
- Continued pre-training: feed the model large volumes of raw domain text to absorb vocabulary and context before SFT.
- RLHF / DPO: reinforcement learning from human feedback — used when output quality requires iterative human preference ranking. More complex but of the highest quality.
Fine-Tuning on Company and Financial Data
What Data Can You Use?
Almost any structured text your company produces can be used to fine tune SLM models. The key is curation and formatting, not volume.
Finance & Accounting
- Earnings call transcripts and analyst Q&A
- Internal financial commentary and variance analyses
- Standardised report templates and audit narratives
- Risk assessment memos and credit committee notes
Legal & Compliance
- Contract clause libraries with approved language
- Regulatory guidance interpretations
- Internal policy documents and compliance FAQs
Operations & Support
- Customer support ticket resolutions (anonymised)
- Internal standard operating procedures (SOPs)
- Product documentation and technical runbooks
Data Preparation Pipeline
When you fine tune SLM models, the quality of training data is the single greatest determinant of performance. Follow this pipeline before any training run:
- Collect: gather source documents from internal systems (SharePoint, Confluence, ERP, ticketing systems)
- Anonymise: redact real names, account numbers, and credentials using tools like Microsoft Presidio or spaCy NER
- Format: convert to JSONL with instruction/output pairs (see example below)
- Review: human spot-check at least 5% of training examples for accuracy and tone
- Split: reserve 10–15% of examples as a held-out validation set
Training data format (JSONL)
{"instruction": "Summarise the following earnings commentary.",
"input": "Revenue for Q3 was $4.2B, up 12% YoY driven by APAC growth...",
"output": "Q3 revenue reached $4.2B, a 12% year-on-year increase,
driven by strong performance in the APAC region."}
Step-by-Step Fine-Tuning Walkthrough
Step 1 — Environment setup
pip install transformers peft bitsandbytes datasets accelerate trl
Step 2 — Load the base model with 4-bit quantisation
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype='bfloat16'
)
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1",
quantization_config=bnb_config, device_map='auto')
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
Step 3 — Configure LoRA adapters
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # Should show ~0.1% of total params
Step 4 — Train
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model=model,
train_dataset=dataset['train'],
eval_dataset=dataset['validation'],
dataset_text_field="text",
args=TrainingArguments(
output_dir="./finance-slm",
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=2e-4,
fp16=True,
)
)
trainer.train()
Step 5 — Deploy on-premises with Ollama
# Convert and serve — no internet required after this point
ollama create finance-assistant -f ./Modelfile
ollama run finance-assistant
Security note on training data
All training must occur on hardware within your security perimeter. If using cloud compute, ensure you have a signed DPA, use a private VPC with no public endpoints, and delete all training data and checkpoints from cloud storage immediately after downloading the final weights.
Best Open Source SLM Models for Enterprise Fine-Tuning
The following open source SLM models are all available on HuggingFace under permissive licences suitable for commercial enterprise use. Download weights directly to your private infrastructure.
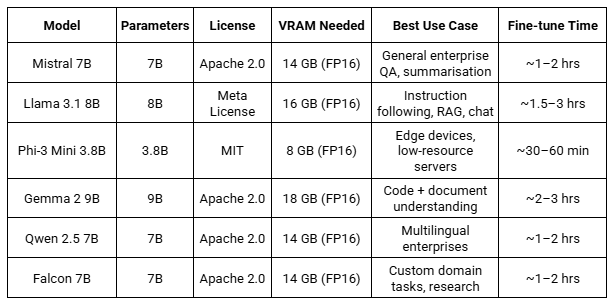
Note: VRAM figures assume FP16 precision. 4-bit QLoRA reduces VRAM requirement by approximately 60%, enabling 7B models to run on 8 GB VRAM during inference.
Open Source SLM Model Selection Guide
- Starting/ general enterprise: Mistral 7B — the best balance of capability, speed, and community support
- Instruction-following and chat: Llama 3.1 8B — Meta’s latest, with excellent benchmark scores
- Resource-constrained deployment: Phi-3 Mini — runs on a laptop GPU, MIT licence for maximum flexibility
- Multilingual organisation: Qwen 2.5 7B — strong multilingual performance across 29 languages
- Code-heavy use cases: Gemma 2 9B — strong code understanding, good for developer tooling
Hardware Requirements and Model Response Time
Hardware Requirements by Scale
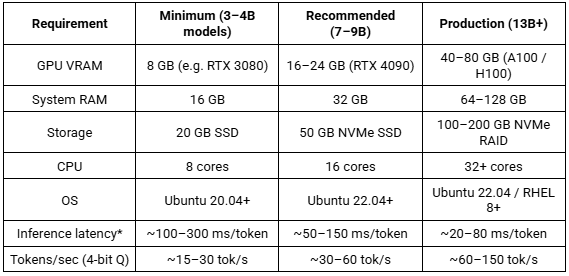
Inference latency measured per output token on a greedy decoding pass. First-token latency (time-to-first-token) is typically 2–5x higher due to prompt processing.
Production Inference Servers
- Ollama: simplest deployment, excellent for internal developer tooling and single-server setups
- vLLM: production-grade, supports OpenAI-compatible API, PagedAttention for high throughput
- llama.cpp: maximum portability, runs on CPU-only hardware if needed, GGUF format
- TGI (Text Generation Inference): HuggingFace’s official server, supports streaming and continuous batching
Conclusion
The proliferation of cloud AI has created an invisible data exfiltration risk that most organisations have not yet fully accounted for. Every prompt sent to a commercial cloud LLM is a potential compliance incident waiting to happen.
Fine-tuning open source SLM on enterprise data offers a structurally different and significantly safer approach. By keeping model weights, training data, and inference entirely within your security perimeter, you eliminate the category of risk, rather than trying to manage it through policy alone.
The technology is no longer experimental. Models like Mistral 7B and Llama 3.1 8B, combined with QLoRA fine-tuning and on-prem inference servers like vLLM, provide enterprise-grade capability on hardware you already own or can procure through your standard IT process.
Build Secure Enterprise AI With Xcelore
If your organisation is evaluating AI adoption, the real differentiator is not just the model, it’s how securely it is built and deployed.
At Xcelore, we provide large language model development services and enterprise AI engineering to help companies design, fine-tune, and deploy secure AI systems at scale. This includes on-premise SLM deployments, custom LLM applications, and end-to-end AI architecture built for compliance, performance, and control.
Whether you are moving from experimentation to production or looking to build private AI systems trained on your internal data, we help you bridge that gap with production-grade engineering.
Talk to us to build enterprise AI systems that stay secure, scalable, and fully under your control.



