
Ever wondered how AI creates breathtaking photorealistic images that dominate social media feeds? Or how synthetic voices now sound almost indistinguishable from humans?
The answer lies in diffusion models — one of the most important breakthroughs in modern artificial intelligence.
From image generators and video synthesis to voice cloning and multimodal AI systems, diffusion models have transformed how machines create content. Unlike earlier generative approaches, these models learn creativity through a structured process of noise transformation, enabling unprecedented realism and stability.
Today, diffusion models power advanced tools such as Stable Diffusion, image editors, AI design assistants, and cinematic content generators. While large language models manage text intelligence, diffusion systems handle visual imagination — together forming the backbone of modern generative AI.
This guide explains how diffusion models work, why they replaced GANs, and how they are reshaping industries worldwide.
Understanding Diffusion Models
Diffusion models are generative AI systems designed to create new data — images, audio, video, or text — by learning patterns from massive datasets.
Their inspiration comes from non-equilibrium thermodynamics, where particles gradually spread over time. AI applies the same idea digitally.
Instead of directly generating an image, the model learns a two-phase transformation:
Forward Diffusion
Noise is slowly added to real data until the original structure disappears.
Reverse Diffusion
The model learns to remove noise step by step, reconstructing meaningful patterns from randomness.
This seemingly simple idea solves one of AI’s biggest problems: generating stable, high-quality outputs consistently.
Why Diffusion Models Replaced GANs
Generative Adversarial Networks (GANs) once dominated image generation but suffered from major limitations:
- Training instability
- Mode collapse (limited diversity)
- Difficult optimization
- Inconsistent realism
Diffusion models introduced predictable learning dynamics and superior scalability.
Key advantages include:
- Stable training process
- Better diversity in outputs
- Higher photorealism
- Improved controllability via prompts
- Strong compatibility with multimodal AI
Because of this reliability, research and industry rapidly shifted toward diffusion architectures.
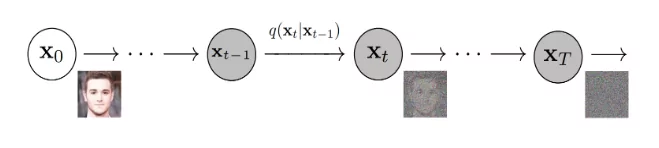
Mathematically, this corruption process forms a fixed Markov chain over T timesteps, where each noisy image at time t directly determines the next state at t+1. The Markovian property ensures each step depends only on the previous state, creating a memoryless progression through the noise schedule.
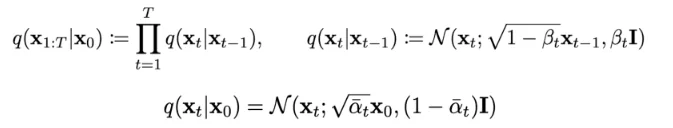
How Schedulers Control the Noise Process
The noise injection follows a carefully controlled pattern via a Scheduler that determines noise amounts at each timestep. The original DDPM research used linear scheduling, where noise parameter βₜ increases uniformly from 0.0001 to 0.02 across timesteps. However, alternative schedules such as the cosine schedule used in Improved denoising diffusion probabilistic models have gained popularity.
These alternatives address linear scheduling’s limitations, which cause overly aggressive information decay, where meaningful image content disappears too quickly in early stages. This rapid degradation creates abrupt corruption that hinders learning efficiency.

The cosine schedule implements a more gradual degradation curve, ensuring images retain meaningful structural information for extended periods during the forward process.
Step 2: Removing Noise - The Reverse Diffusion Process
Unlike the forward process, reverse diffusion is computationally intractable because directly calculating q(xₜ₋₁|xₜ) is mathematically impossible. This reverse probability distribution cannot be computed analytically.
Deep neural networks solve this by approximating the reverse process. These networks estimate the full noise present in an image at time step t. During training, predicted noise is compared against actual added noise, enabling supervised learning of accurate noise estimation.
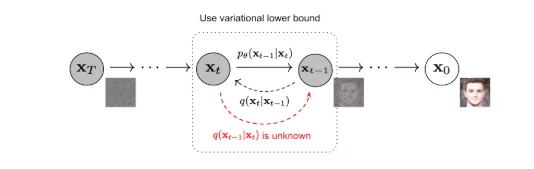
During inference, the network predicts total noise at timestep t but removes only a fraction according to the scheduler. While removing all noise in one step seems logical, empirical research shows this causes unstable, poor-quality results. Instead, gradual noise removal across multiple timesteps provides superior stability and quality, allowing refined corrections at each stage to progressively transform noise into high-quality images.
The Neural Network Behind Diffusion Models (U-Net Explained)
Diffusion models typically use U-Net variants to approximate the reverse diffusion process. U-Net is ideal because it maintains identical input-output dimensionality, which the model requires (except for super-resolution variants).
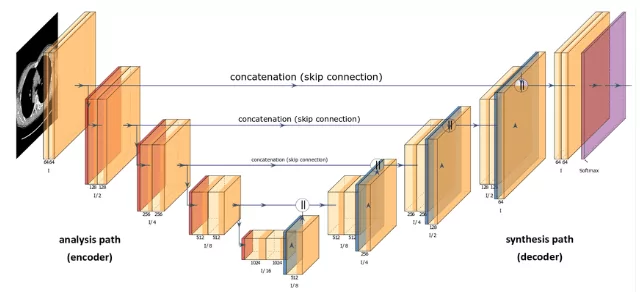
The DDPM outlines key architectural choices:
- Encoder and decoder paths have equal levels with a bottleneck block between them
- Each encoder stage uses two Residual Blocks with convolutional downsampling (except the final level)
- Each decoder stage uses three Residual Blocks with x2 nearest neighbor upsampling and convolutions
- Skip connections link decoder stages to corresponding encoder stages
- Attention modules operate at a single feature map resolution
- Timestep t is encoded as time embeddings, similar to Sinusoidal Positional Encoding from Transformers
Time embeddings inform the network about the current diffusion state, helping it determine noise levels and adjust denoising accordingly. Lower timesteps contain less noise than higher time steps, guiding the model’s noise-removal decisions.
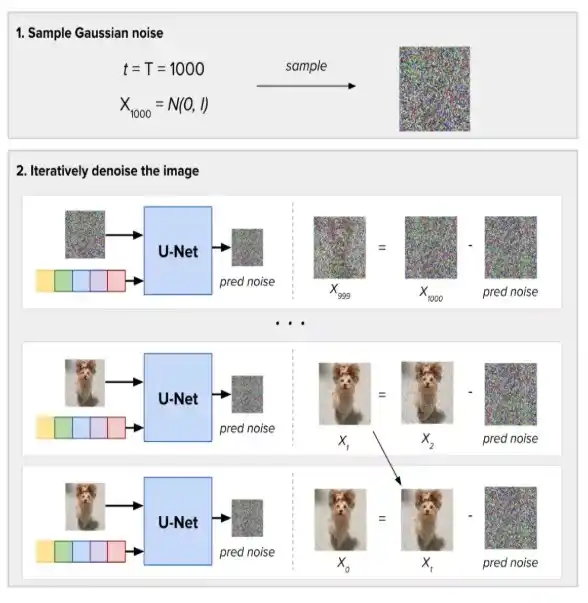
Here’s an illustration of the complete forward/reverse diffusion process:

How the Model Learns: Calculating the Loss Function
To train a diffusion model, the goal is to learn reverse Markov transitions that maximize the likelihood of the training data. This amounts to minimizing the Variational Lower Bound (VLB) on negative log-likelihood. Though called a “lower bound,” it’s technically an upper bound, the negative of the Evidence Lower Bound (ELBO), but we follow standard literature terminology. Practically, maximizing likelihood means minimizing the negative log likelihood
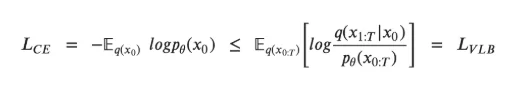
To make each equation term analytically computable, the objective can be rewritten as a combination of the KL Divergence and entropy terms.
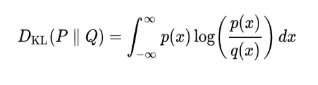
How Diffusion Models Are Trained
During each training batch, the model follows a systematic learning process:
- Random Timestep Sampling: A random timestep t is selected for each training sample (e.g., an image) in the batch, thereby determining the noise level to be applied.
- Noise Injection: Gaussian noise is added to the clean images using the closed-form formula, with noise intensity corresponding to the sampled timestep t.
- Time Embedding Conversion: The timesteps are converted into numerical embeddings that can be processed by the U-Net or similar neural network architectures.
- Noise Prediction: The model is fed noisy images and time embeddings to predict the exact noise present in each corrupted image.
- Loss Calculation: The model’s predicted noise is compared with the added noise to compute the training loss function.
- Parameter Updates: Model parameters are updated through backpropagation based on the calculated loss, gradually improving noise prediction accuracy.
This training cycle repeats across epochs using the same image dataset, but crucially samples different timesteps for each image in different epochs. This varied time step sampling ensures the model learns to reverse the diffusion process effectively at any noise level, significantly enhancing its generalization and adaptability.

How Diffusion Models Generate Images from Prompts
When using Diffusion Models for Image Generation, the process differs since no input image exists. Instead, we start by sampling random Gaussian noise and specifying the number of denoising steps (T) for image generation. At each step, the diffusion model predicts the complete noise present in the current noisy image using the timestep as input. However, it removes only a portion of this predicted noise rather than all of it. After completing the T inference steps of gradual denoising, we obtain the final generated image.
Real-World Applications of Diffusion Models
Diffusion models have moved beyond research labs and are now embedded in real production workflows across industries. Their real strength lies in modeling patterns of reality — visuals, sound, motion, and structure — rather than simply generating images. Businesses use them to accelerate creativity, automate asset creation, and simulate complex environments. Instead of replacing traditional tools, diffusion models enhance productivity and decision-making. Today, they function as practical infrastructure supporting digital creation, experimentation, and scalable innovation across multiple sectors.
Creative Media: Redefining Digital Creativity
Creative professionals increasingly use diffusion models to explore ideas faster and reduce production friction. Artists and filmmakers can generate concept visuals, storyboards, and stylistic experiments before committing resources to full production. This enables rapid ideation and creative testing without large teams or expensive equipment. Human creators remain in control of artistic direction while AI handles execution speed. As a result, creativity shifts from manual design work toward imaginative exploration and visual storytelling.
Marketing & Advertising: Content at the Speed of Ideas
Marketing teams face constant demand for fresh visuals across platforms. Diffusion models allow brands to generate campaign imagery, localized creatives, and multiple design variations instantly. Instead of organizing repeated photoshoots, marketers can prototype ideas quickly and optimize campaigns based on performance data. Faster experimentation leads to smarter targeting and more adaptive storytelling. Creative production becomes continuous rather than campaign-based, enabling brands to react instantly to trends and audience behavior.
Gaming & Virtual Worlds: Building Infinite Digital Environments
Game development traditionally requires extensive manual asset creation. Diffusion models streamline this process by generating textures, environments, and character variations automatically. Developers define artistic guidelines while AI produces scalable world elements that remain visually consistent. This reduces development time and allows teams to build larger, more immersive virtual spaces. As metaverse environments and simulations grow, diffusion technology enables dynamic worlds that evolve instead of remaining static digital environments.
Healthcare Imaging: Advancing Medical Research and Training
Healthcare organizations use diffusion models to overcome limitations in medical data availability. AI can generate synthetic medical images that preserve statistical accuracy while protecting patient privacy. These datasets help train diagnostic systems, simulate rare medical conditions, and improve imaging quality. Diffusion techniques also assist in noise reduction and reconstruction of MRI or CT scans. By enhancing both research and diagnostics, the technology supports faster innovation while maintaining strict ethical and regulatory standards.
E-commerce: Reinventing Product Visualization
Online retail depends heavily on visual presentation, yet traditional photography is costly and difficult to scale. Diffusion models allow businesses to create product visuals in multiple environments without physical setups. Brands can generate lifestyle scenes, seasonal campaigns, and personalized shopping previews from a single product image. This flexibility improves customer engagement while reducing operational costs. The shopping experience becomes more interactive, visually rich, and adaptable to individual consumer preferences.
Voice & Audio AI: Human-Level Synthetic Communication
Diffusion models are expanding into audio generation, enabling highly realistic speech and sound synthesis. Modern systems capture tone, emotion, and natural timing far better than earlier text-to-speech technologies. Applications include virtual assistants, audiobook narration, gaming dialogue, and accessibility tools. Businesses can create multilingual voice interfaces and personalized communication experiences at scale. As audio AI improves, interaction between humans and machines becomes increasingly natural and conversational.
A Universal Creative Infrastructure
Across industries, diffusion models are emerging as foundational creative infrastructure. They convert ideas into production-ready outputs by simulating visual, auditory, and environmental patterns. Similar to how cloud computing transformed software development, diffusion technology is reshaping digital creation workflows. Organizations now view generative AI not as experimentation but as operational capability. The focus has shifted from whether to adopt AI toward how deeply it can enhance innovation and productivity.
Diffusion Models and the Future of Generative AI
Diffusion models represent one of the most important breakthroughs in artificial intelligence since the emergence of deep learning. While earlier generative systems attempted to imitate creativity through pattern replication, diffusion models introduced a fundamentally different philosophy: learning creation through controlled destruction and reconstruction.
At their core, diffusion systems learn how real-world data behaves by gradually corrupting information with noise and then learning how to reverse that process. This seemingly simple idea allows AI to understand structure, texture, relationships, and context at an exceptionally deep level. Instead of memorizing images or sounds, the model learns how reality forms — which is why outputs appear remarkably coherent and lifelike.
Why Diffusion Models Became the Dominant Generative Approach
Earlier generative models like GANs produced impressive visuals but were difficult to train consistently. Diffusion models introduced a more stable probabilistic learning process that improved output quality and diversity. They scale effectively with modern computing resources and support controllable generation through prompts and conditioning. These advantages enabled their transition from research experiments to production systems. Today, many leading generative AI platforms rely on diffusion architectures for reliable large-scale content creation.
From Image Generation to Multimodal Intelligence
Diffusion technology is rapidly expanding beyond images into multimodal AI capabilities. Researchers are applying diffusion principles to video generation, 3D environments, speech synthesis, and scientific simulations. This evolution allows AI systems to combine text, vision, sound, and motion within unified workflows. Rather than producing isolated outputs, models can now simulate complex digital experiences. Diffusion models therefore act as a bridge between perception and imagination in next-generation AI systems.
Human Creativity Is Not Being Replaced — It Is Being Amplified
Diffusion models shift human roles from manual production toward creative supervision and strategy. Professionals focus on ideation, storytelling, and experimentation while AI accelerates execution. Designers refine prompts, marketers test multiple concepts quickly, and researchers prototype ideas faster than traditional methods allow. Creativity becomes iterative and exploratory instead of resource-limited. AI serves as a collaborative partner that expands human creative potential rather than replacing it.
Economic and Industrial Transformation
Generative AI powered by diffusion models is reshaping economic structures across creative and technical industries. Production costs decrease while innovation speed increases, allowing smaller teams to compete globally. Industries such as advertising, gaming, design, and simulation benefit from scalable content generation. Personalized digital experiences can now be delivered efficiently at large scale. This transformation positions generative AI as essential digital infrastructure for future business operations.
The Next Frontier: Real-Time Generative Systems
Research is moving toward faster diffusion methods capable of real-time generation. New techniques reduce denoising steps, enabling interactive image, video, and environment creation. Future systems may generate immersive experiences instantly based on user interaction. On-device models and adaptive learning systems will further increase accessibility. These developments blur the boundary between creation and experience, allowing AI to simulate reality dynamically.
Ethical Responsibility and Governance
As generative capabilities expand, ethical governance becomes increasingly important. Synthetic media raises concerns around misinformation, intellectual property rights, and dataset transparency. Responsible AI development requires safeguards such as watermarking, provenance tracking, and bias monitoring. Building public trust will depend on transparent deployment practices and regulatory collaboration. Long-term success of diffusion technology relies on balancing innovation with accountability.
Conclusion: Diffusion Models and Their Future in AI
Diffusion Models for Image Generation have completely changed how AI creates digital content. By learning to add and remove noise step by step, they generate high-quality images, voices, and even text with incredible accuracy.
Their stability, scalability, and realistic results make them more reliable than older models like GANs. From creating photorealistic images to powering lifelike voice synthesis, diffusion models are now at the heart of modern generative AI — shaping everything from art to communication.
Turn Innovation into Impact with Xcelore
Generative AI isn’t the future; it’s already here. At Xcelore, we help businesses and creators harness the power of generative AI solutions to build smarter, more dynamic solutions. Partner with Xcelore today to bring your next AI project to life.
FAQs
-
1. What is the diffusion model?
A diffusion model is a type of generative AI model that learns to create new images (and sometimes sounds or videos) from random noise. During training, it learns to add noise to real images slowly and then remove it step by step. Once trained, it can start with pure noise and “denoise” it into a brand-new, realistic image.
-
2. What is the difference between diffusion model and LLM?
A diffusion model and a large language model (LLM) do very different things. LLMs like ChatGPT work with text; they read and write language. On the other hand, diffusion models work with visual data; they generate images by turning random noise into clear pictures.
-
3. Can stable diffusion model run in LMStudio?
Yes. LM Studio can run some Stable Diffusion models through its “Discover” tab, where you can find and download compatible models to try out image generation directly in the app.



